DS III - Making a Data Plane Fly.
• • ☕️☕️☕️ 15 min readOK, now we have something resembling a platform that we can develop against, let’s talk about how our application will actually work (finally, you gasp). This is an application which will collect data from Twitter and make it available to others.
At the top level, we need to think about;
- How long we want to store the data for - is it just until the next service has time to access it, or is it a permanent record?
- Do the individual records have any sort of history (for example, how do we treat edits to Tweets) and do we want to retain all of it?
- Does the structure of the data change? If so, how do we manage changes to the data structure such that consumers expecting a previous structure can consume the new structure?
- Velocity, variety and volume of data.
Translating through to a technical design -
- We want to store the data forever, this is a data storage system, not a messaging system.
- For the sake of simplicity, we will overwrite previous versions of tweets.
- We do not control the data structure, and should therefore expect it to change.
- We really only have one type of data present, which is tweets and we can scale for velocity and volume using more instances in our Kafka consumer group (but see the note in italics below, and my forthcoming post on Kafka for some roadbumps in this story.).
Translating through to the implementation - (1) and (2) suggest that what we want is the most recent version of each record emitted stored forever - so we’ll need to set our Kafka topics to use log compaction. We then just need to ensure that the duplicated data is retained for long enough that all consumers can pick it up before old versions are deleted.
Requirement (3) can be addressed by using Avro’s schema evolution (next post), while velocity is addressed by using Kafka (throughput can be increased by horizontal scaling of brokers and application instances), volume is the same story, and the variety concern is not very relevant here.
NB: I believe that there is something in the developer’s agreement with Twitter to the effect that tweets need to be deleted from your app if a corresponding StatusDeletionNotice if received. I am not touching on this, because my assumption is that you are running a temporary environment which is deleting ALL data on every restart. If this is not the case, and you get sued or something, you can’t say I didn’t warn you…
Retention
We’re using log compaction to retain the most recent iteration of each tweet, in contrast to the standard cleanup strategy - delete - log compaction keeps the most recent value for each key. Log compacted topics have a cleanup.policy set to compact, but the conditions under which the compaction actually takes place are a bit confusing. The delete option would use retention.bytes (which controls maximum topic size, and is disabled with a value of -1 by default) as well as retention.ms, which controls the maximum age of a record before deletion occurs (and is not to be confused with delete.retention.ms).
But when we use a compaction cleanup strategy, it actually uses min.cleanable.dirty.ratio - the proportion of log space consumed by old records as a value between 0 and 1. Complicating the situation further is that no compaction can take place before the value specified in min.compaction.lag.ms, which we can use to our advantage to ensure that consumers have an opportunity to read the data before it is compacted. Note that what is missing is an ability to set a corresponding max.compaction.lag.ms, so don’t think of log compaction as a way to fake a database UPDATE operation (a common error), it isn’t - it’s an INSERT. For more ways you can think incorrectly about Kafka, see the previous post.
Managing dev and production configs
So we have a pretty good idea of the low level/transport layer for the data now, and we’ve come up with a way to use Kafka to address points one and two from our technical design to get data across the cluster in a reasonable and safe way. Refer to twitter-topic.conf for a summary of the appropriate settings, if you’ve been following the above they should make sense.

The only problem is that we only have a single broker on our cluster, so how can we have three replications? Trying to create this topic will result in an error. I’m leaving it that way, because that’s how we’d like to see it in production, where we won’t be able to change that value - because we’ll be using source control or a CI/CD pipeline to push our changes and definitely won’t be creating any topics by hand… right..?
I may post about building a tool to parse and apply these files later, but overriding these kinds of configs in our dev environment is what etcd is there for (among other things), and we’ll cover that in a future post.
Producing messages to Kafka from Scala
Grab the Github repo from here. If (like me) you’re really a Python engineer and not wholly impressed with the whole idea of compilation generally, you’ll probably find this folder structure to be a dog’s breakfast. Sorry.
One click deploy - Wow.
I’m even more sorry to report that this is a standard Scala project, with a structure common to those using the fairly ubiquitous(ly derided) build tool sbt. Do not blame me, I do not make the rules. While other options (Ammonite especially) exist, we couldn’t demo all of the Avrohugger things we’d like to from there, so we may as well get the pain over with early.
You can install sbt yourself, Google is your friend if you have difficulty. You’ll also likely want an IDE suited to Scala, your main options being IDEA, VS Code or Atom with Metals, or hacking something together using Ammonite, an editor, and some way to work with an SBT file (which might just be manually copying stuff given the top hit for “sbt ammonite” on Google is broken).
None of these options is great, but IDEA is quick to get running (although it frequently produces false positive errors and other strange behaviours).
Where’s my code? Five levels deep.

Ah… Yes. We all know that one of the best ways to convince your boss that you’ve done some work is to completely bamboozle them, and often some sort of directory structure Inception is just the ticket. Scala lore therefore institutes unquestionable rules stating that:
- Only one class, in only one file, shall exist per folder.
- That every class shall exist in its own namespace, inside one of those folders.
- That the namespaces defined in
packagestatements and folder structure shall reflect each other perfectly.
Follow them, and I guarantee that by the time your boss has finished clicking through the endlessly nested hierarchy of filesystem goodies, they’ll have forgotten what they were looking for in the first place; and will not ask you questions. Truly, Scala is an enterprise-fit anguage.
I note that I have severely violated these rules in this tute by basically chucking everything in the same folder (main.scala.io.github.milesgarnsey.blog). This has the pleasing upside that I don’t have to import my own code, and suits my purposes in that my reader may actually understand some of what is going on.
To start with, have a look at the build system files - especially;
build.sbt./project/plugins.sbt./project/.sbtopts
(1) defines the libraries you want to use, and (in our case) (2) defines an sbt plugin to build Docker containers. Finally, (3) saves us a lot of head scratching down the line when we start hitting mysterious heap errors - which is something that can happen during both compilation and run phases, thanks to the joys of the JVM. sbt creates plenty of additional cruft (which is both distracting and infuriating), but most of it can be ignored.
If we’re modern developers, it would be nice if we could get this into our cluster relatively seamlessly, but (from the second post in this series) we know that there are some complexities behind getting docker images into minikube, let alone unpackaged application code.
What we didn’t mention, is that to access the docker daemon in minikube, we can actually run eval $(minikube docker-env), which will then direct the commands we’re typing into our regular Docker client back into the Minikube VM.
eval $(minikube docker-env)
(cd .. && sbt docker:publishLocal)
kubectl --namespace=dev delete pods,replicasets.apps -l app=data-engineering-blog
kubectl apply -f deploy.yaml
kubectl logs -f -p -l "app=data-engineering-blog" --all-containers=true
So because we also have the sbt packager set up to use Docker, we can actually just run sbt docker:publishLocal and sbt will publish to Minikube. I’ve included a K8s manifest to ensure that this all works correctly once we hit deploy. More likely, you will just run the script above - deploy.sh without thinking too much about it. Congratulations, laziness is becoming in a data scientist, and you’re developing well in this regard.
We could get a lot fancier and do this with CI/CD servers which hook up to Github (GoCD, Jenkins spring to mind), and private Docker Registries which receive their output images and redeploy the app. There are some nice tools that do all of this stuff in a single place (Gitlab for example), but really, what we have here is pretty effective, and almost zero config is required. When you’re moving jobs frequently (e.g. if you have the joy of being a consultant, contractor, or other variety of gun for hire as I do), simple deployment pipelines that rely mostly on basic linux tools are great.
Now let’s have a look at this compiled-language-business shall we? Our sbt build definition told us where the main class can be found - Compile / mainClass := Some("main.scala.io.github.milesgarnsey.blog.Entrypoint"), let’s start there.
Scala: an entirely rational and very consistent language
First off, we can see that our Entrypoint is an object (not a class, because we need something which is a singleton to launch the App). It extends LazyLogging which is why we can call methods of logger without declaring it. Go research these terms if you aren’t familiar with them. Formalities dealt with, we’re then loading some configs via val config = ConfigFactory.load().
object Entrypoint extends App with LazyLogging {
logger.info("Initialising Data engineering Part III demo app...")
val config = ConfigFactory.load()
val producer = new ToyProducer(
config.getString("kafka-brokers"),
config.getString("output-topic"))
val sendresult = producer.sendmessage(config.getString("output-message"))
logger.info(sendresult.toString)
Thread.sleep(3600000)
}
While config wrangling is not exciting ML functionality, one of the things I realised early when working with Scala was that compilation via SBT is agonisingly slow. To avoid spending half our lives waiting for the build cycle to complete and the container to deploy (which is even slower in cloud development environments, especially for larger containers) it helps to have a config file where you can change settings quickly.
Note that agonisingly slow means 45–120 seconds (if it is taking longer for a project like this you’re doing something wrong). This is agonising if you’re making a bunch of changes in quick succession, don’t know the language well, and want to test after each change. That would be at least 10–20 recompiles per hour, which if you multiply it out comes out to you having spend something like a quarter of your hour waiting for recompilation.
We instantiate a ToyProducer class and pass some of the configs - we could pass the whole config, but that would diminish the modularity of the code.
Diving into what this ToyProducer class actually does, we’ll see that it instantiates a Java Properties object to receive our configs, which tips us off that this may be a Java object being accessed from Scala. When we have to do this we basically lose a lot of the elegance of Scala, so the “Scala can access the Java ecosystem” argument actually isn’t a great one (unless you enjoy spending your life writing extremely awkward interfaces to loosely supported languages).
class ToyProducer(bootstrapServers: String, topic: String) {
val props = new Properties
props.put("bootstrap.servers", bootstrapServers)
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
val client = new KafkaProducer[String,String](props)
def sendmessage(message:String): RecordMetadata= {
val res = client.send(new ProducerRecord[String,String](topic=topic,K="No key here...",V=message))
res.get()
}
}
Once we’ve gotten over the nauseating getty/settyness of the interface, the clunkiness becomes particularly clear on line 13 - try to run deploy.sh in the deploy folder… Yes, you receive an error helpfully telling you that there is something wrong with your method signature. This is because Java methods (even if called from Scala) can’t take named parameters. Remove the parameter names and try again…
How can you log that the logging is broken if the logging is broken so you can’t log that…
OK, it now builds and deploys, jump into your kubernetes dashboard (minikube dashboard in your console will do it - please read the previous posts…), select your dev namespace and go to overview; you should see your replica set running there. But sadly the container has failed… So much for Scala catching most errors at compilation time…
Why did it fail? Who knows, your logging is broken - at least you can claim that 'we are not aware of any issues’.
The logging framework scans your classpath for logging implementations to bind to, and you have one in both logback-classic, as well as the helpfully named SLF4J-Log4J, which has been imported as a transitive dependancy (a dependancy contained in a library you are importing). Honestly, where did you even learn to Scala, you must have had a hopeless teacher.
To fix this, we need to go back to our SBT file and seperate the Seq containing our library dependancies into two, one of which explicitly excludes the SLF4J organisation -
libraryDependencies ++= Seq(
"org.apache.kafka" %% "kafka-streams-scala" % "2.2.0",
"io.confluent" % "kafka-avro-serializer" % "3.1.2",
"org.apache.kafka" % "kafka_2.9.2" % "0.8.2.2",
"com.typesafe.scala-logging" %% "scala-logging" % "3.9.2",
"com.typesafe" % "config" % "1.3.4",
"ch.qos.logback" % "logback-classic" % "1.0.13")
becomes -
libraryDependencies ++= Seq(
"org.apache.kafka" %% "kafka-streams-scala" % "2.2.0",
"io.confluent" % "kafka-avro-serializer" % "3.1.2",
"org.apache.kafka" % "kafka_2.9.2" % "0.8.2.2",
"com.typesafe.scala-logging" %% "scala-logging" % "3.9.2",
"com.typesafe" % "config" % "1.3.4").map(_.exclude("org.slf4j", "slf4j-log4j12")),
libraryDependencies ++= Seq("ch.qos.logback" % "logback-classic" % "1.0.13")
The meaning should be clear to anyone who understands mapping an array in any language. We apply the same operation (exclude) to every element (_ in Scala, which allows us to anonymously refer to the elements being mapped, sadists, and those of us who prefer clarity at the expense of brevity might prefer the verbosity of x=>x.exclude(...)). We then add logback-classic back in without the exclusion.
Where’s Kafka running again?
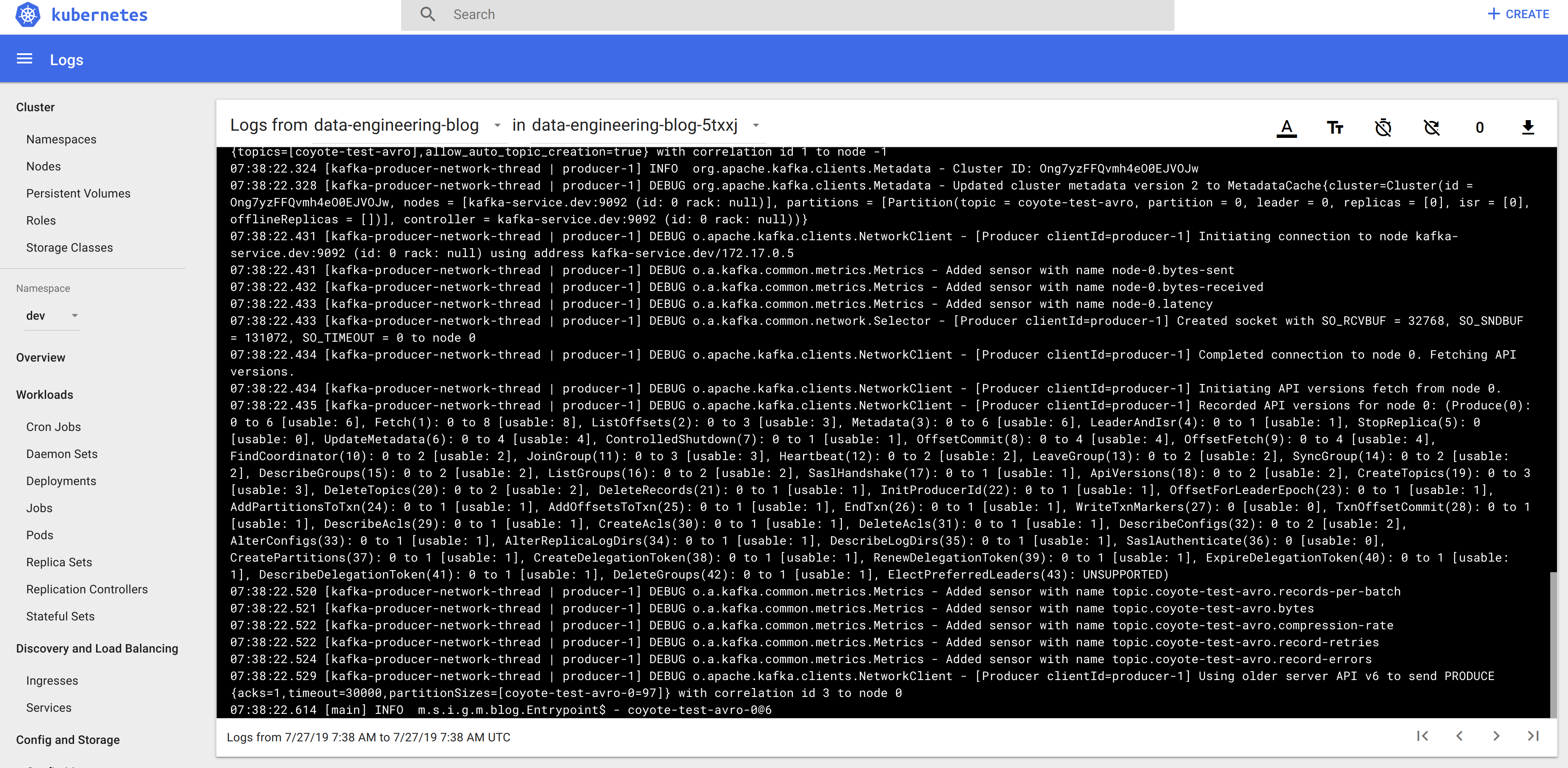
Redeploy again and check the logs…
Oh no… Network errors from Kafka - that doesn’t look too healthy. If we look closely we can see that it is failing to talk to localhost - but hang on, that doesn’t seem quite right… In production, the applications talking to Kafka shouldn’t be on the same machine as Kafka itself - our dev environment has been set up to replicate this hasn’t it? So change the application.conf to talk to our Kubernetes Kafka service at kafka-service.dev instead of localhost.
app-name="data-engineering-blog"
kafka-brokers="kafka-service.dev:9092"
schema-registry="kafka-service.dev:8081"
output-topic="coyote-test-avro"
output-message="I'm a message!!"
Redeploy, check the logs - all looks pretty healthy… And if you use the kubectl port-forward --namespace=dev service/kafka-service 3030:3030 command then head across to localhost:3030 to access the Landoop UI, you’ll see there are some messages in your Kafka topic.